
The increasing availability of digital text in diverse languages and scripts presents a significant challenge for natural language processing (NLP). Multilingual pre-trained language models (mPLMs) often struggle to handle transliterated data effectively, leading to performance degradation. Addressing this issue is crucial for improving cross-lingual transfer learning and ensuring accurate NLP applications across various languages and scripts, which is essential for global communication and information processing.
Current methods, including models like XLM-R and Glot500, perform well with text in their original scripts but struggle significantly with transliterated text due to ambiguities and tokenization issues. These limitations degrade their performance in cross-lingual tasks, making them less effective when handling text converted into a common script such as Latin. The inability of these models to accurately interpret transliterations poses a significant barrier to their utility in multilingual settings.
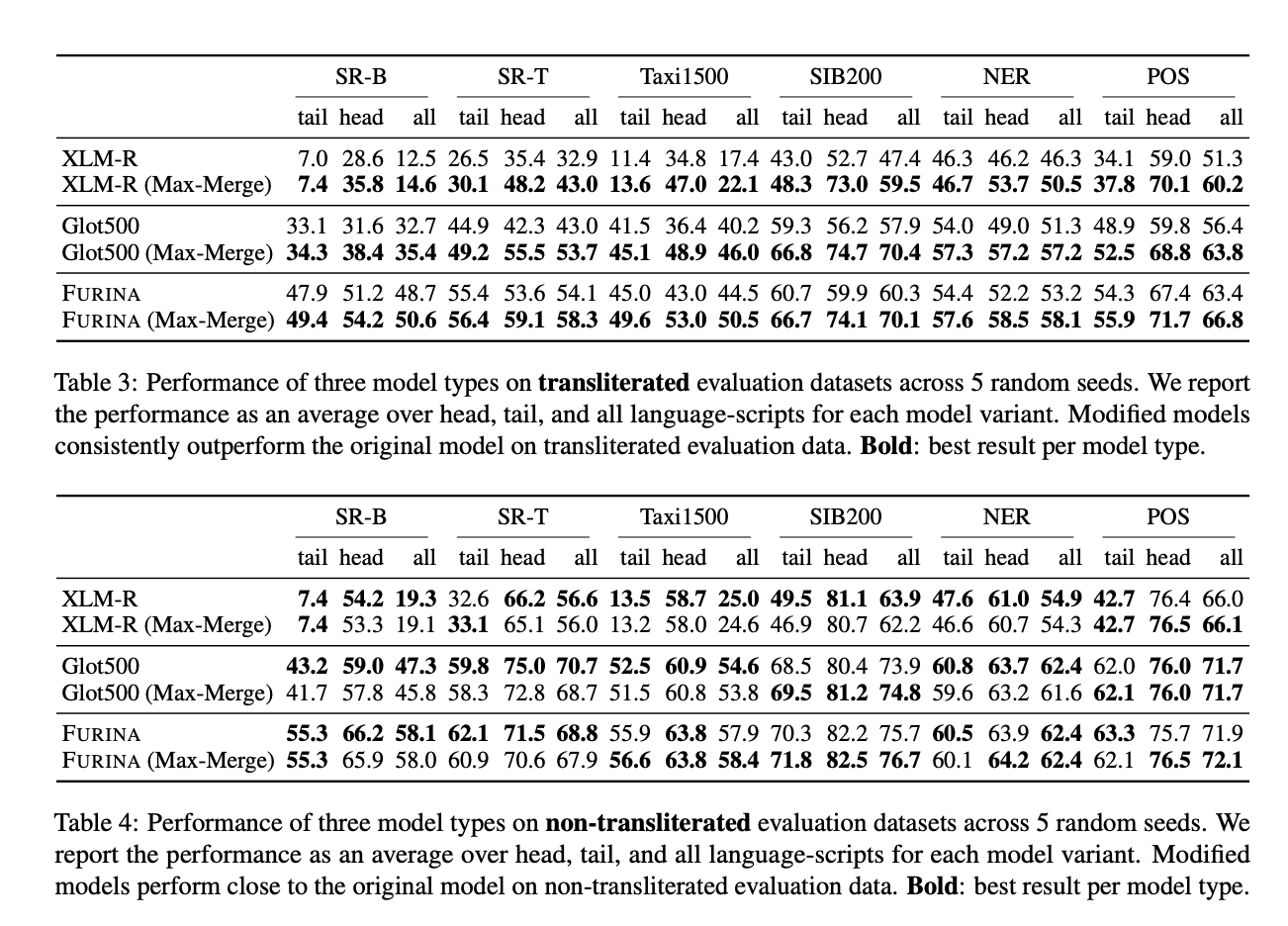
Researchers from the Center for Information and Language Processing, LMU Munich, and Munich Center for Machine Learning (MCML) introduced TRANSMI, a framework designed to enhance mPLMs for transliterated data without requiring additional training. TRANSMI modifies existing mPLMs using three merge modes—Min-Merge, Average-Merge, and Max-Merge—to incorporate transliterated subwords into their vocabularies, thereby addressing transliteration ambiguities and improving cross-lingual task performance.
TRANSMI integrates new subwords tailored for transliterated data into the mPLMs’ vocabularies, particularly excelling in the Max-Merge mode for high-resource languages. The framework is tested using datasets that include transliterated versions of texts in scripts such as Cyrillic, Arabic, and Devanagari, showing that TRANSMI-modified models outperform their original versions in various tasks like sentence retrieval, text classification, and sequence labeling. This modification ensures that models retain their original capabilities while adapting to the nuances of transliterated text, thus enhancing their overall performance in multilingual NLP applications.
The datasets used to validate TRANSMI span a variety of scripts, providing a comprehensive assessment of its effectiveness. For example, the FURINA model using Max-Merge mode shows significant improvements in sequence labeling tasks, demonstrating TRANSMI’s capability to handle phonetic scripts and mitigate issues arising from transliteration ambiguities. This approach ensures that mPLMs can process a wide range of languages more accurately, enhancing their utility in multilingual contexts.
The results indicate that TRANSMI-modified models achieve higher accuracy compared to their unmodified counterparts. For instance, the FURINA model with Max-Merge mode demonstrates notable performance improvements in sequence labeling tasks across different languages and scripts, showcasing clear gains in key performance metrics. These improvements highlight TRANSMI’s potential as an effective tool for enhancing multilingual NLP models, ensuring better handling of transliterated data and leading to more accurate cross-lingual processing.
In conclusion, TRANSMI addresses the critical challenge of improving mPLMs’ performance on transliterated data by modifying existing models without additional training. This framework enhances mPLMs’ ability to process transliterations, leading to significant improvements in cross-lingual tasks. TRANSMI offers a practical and innovative solution to a complex problem, providing a strong foundation for further advancements in multilingual NLP and improving global communication and information processing.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.