
Understanding RAG Part IV: RAGAs & Other Evaluation Frameworks
Image by Editor | Midjourney & Canva
Be sure to check out the previous articles in this series:
Retrieval augmented generation (RAG) has played a pivotal role in expanding the limits and overcoming many limitations of standalone large language models (LLMs). By incorporating a retriever, RAG enhances response relevance and factual accuracy: all it takes is leveraging external knowledge sources like vector document bases in real-time, and adding relevant contextual information to the original user query or prompt before passing it to the LLM for the output generation process.
A natural question arises for those diving into the realm of RAG: how can we evaluate these far-from-simple systems?
There exist several frameworks to this end, like DeepEval, which offers over 14 evaluation metrics to assess criteria like hallucination and faithfulness; MLflow LLM Evaluate, known for its modularity and simplicity, enabling evaluations within custom pipelines; and RAGAs, which focuses on defining RAG pipelines, providing metrics such as faithfulness and contextual relevancy to compute a comprehensive RAGAs quality score.
Here’s a summary of these three frameworks:
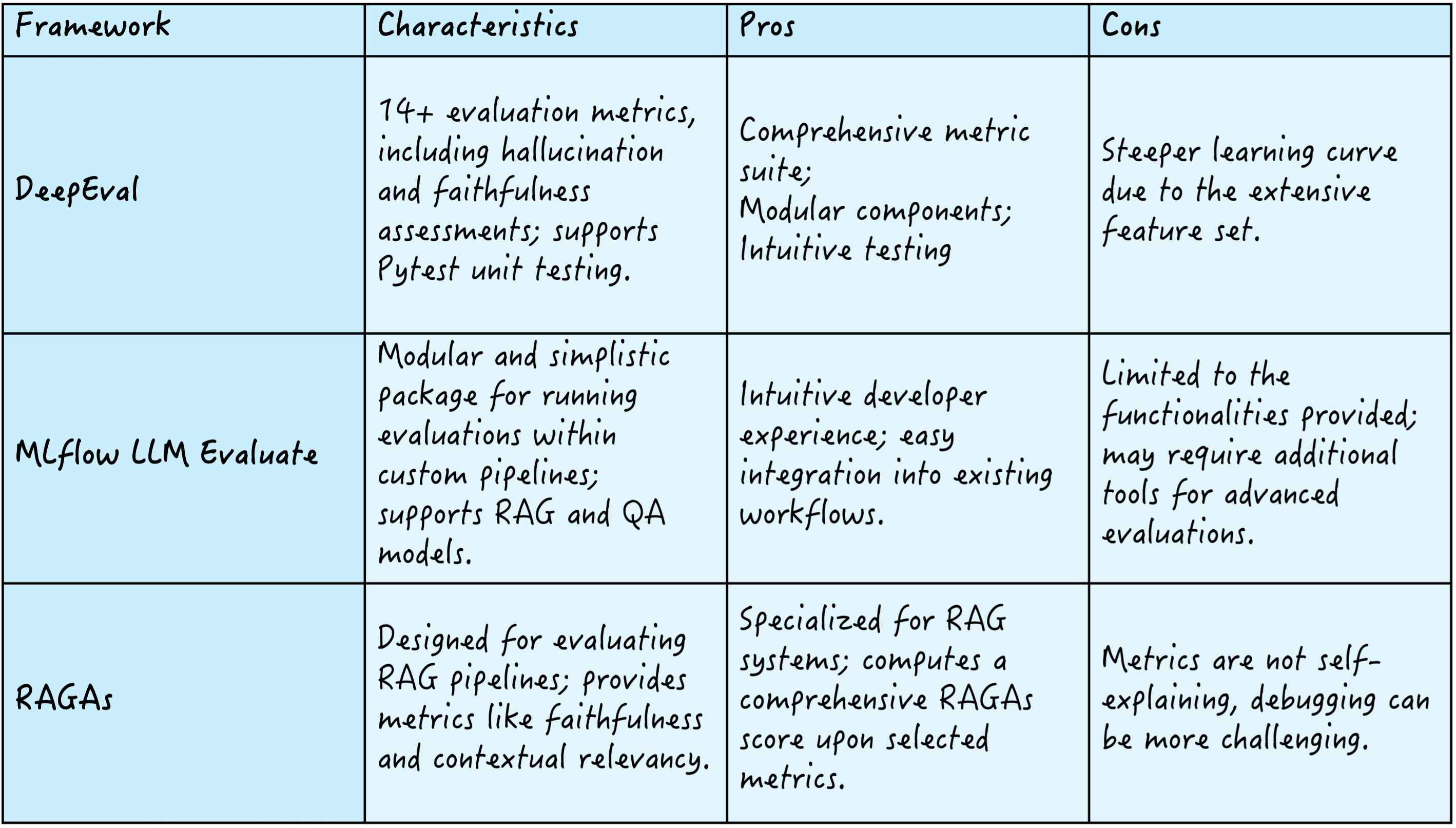
RAG evaluation frameworks
Let’s further examine the latter: RAGAs.
Understanding RAGAs
RAGAs (an abbreviation for retrieval augmented generation assessment) is considered one of the best toolkits for evaluating LLM applications. It succeeds in evaluating the performance of a RAG system’s components &madsh; namely the retriever and the generator in its simplest approach — both in isolation and jointly as a single pipeline.
A core element of RAGAs is its metric-driven development (MDD) approach, which relies on data to make well-informed system decisions. MDD entails continuously monitoring essential metrics over time, providing clear insights into an application’s performance. Besides allowing developers to assess their LLM/RAG applications and undertake metric-assisted experiments, the MDD approach aligns well with application reproducibility.
RAGAs components
- Prompt object: A component that defines the structure and content of the prompts employed to elicit responses generated by the language model. By abiding with consistent and clear prompts, it facilitates accurate evaluations.
- Evaluation Sample: An individual data instance that encapsulates a user query, the generated response, and the reference response or ground truth (similar to LLM metrics like ROUGE, BLEU, and METEOR). It serves as the basic unit to assess an RAG system’s performance.
- Evaluation dataset: A set of evaluation samples used to evaluate the overall RAG system’s performance more systematically, based on various metrics. It aims to comprehensively appraise the system’s effectiveness and reliability.
RAGAs Metrics
RAGAs offers the capability of configuring your RAG system metrics, by defining the specific metrics for the retriever and the generator, and blending them into an overall RAGAs score, as depicted in this visual example:
Let’s navigate some of the most common metrics in the retrieval and generation sides of things.
Retrieval performance metrics:
- Contextual recall: The recall measures the fraction of relevant documents retrieved from the knowledge base across the ground-truth top-k results, i.e., how many of the most relevant documents to answer the prompt have been retrieved? It is calculated by dividing the number of relevant retrieved documents by the total number of relevant documents.
- Contextual precision: Within the retrieved documents, how many are relevant to the prompt, instead of being noise? This is the question answered by contextual precision, which is computed by dividing the number of relevant retrieved documents by the total number of retrieved documents.
Generation performance metrics:
- Faithfulness: It evaluates whether the generated response aligns with the retrieved evidence, in other words, the response’s factual accuracy. This is usually done by comparing the response and retrieved documents.
- Contextual Relevancy: This metric determines how relevant the generated response is to the query. It is typically computed either based on human judgment or via automated semantic similarity scoring (e.g., cosine similarity).
As an example metric that bridges both aspects of a RAG system — retrieval and generation — we have:
- Context utilization: This evaluates how effectively an RAG system utilizes the retrieved context to generate its response. Even if the retriever fetched excellent context (high precision and recall), poor generator performance may fail to use it effectively, context utilization was proposed to capture this nuance.
In the RAGAs framework, individual metrics are combined to calculate an overall RAGAs score that comprehensively quantifies the RAG system’s performance. The process to calculate this score entails selecting relevant metrics and calculating them, normalizing them to move in the same range (normally 0-1), and computing a weighted average of the metrics. Weights are assigned depending on each use case’s priorities, for instance, you might want to prioritize faithfulness over recall for systems requiring strong factual accuracy.
More about RAGAs metrics and their calculation through Python examples can be found here.
Wrapping Up
This article introduces and provides a general understanding of RAGAs: a popular evaluation framework to systematically measure several aspects of RAG systems performance, both from an information retrieval and text generation standpoint. Understanding the key elements of this framework is the first step towards mastering its practical use to leverage high-performing RAG applications.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.