

Understanding RAG Part VII: Vector Databases and Indexing Strategies
Image by Editor | Midjourney & Canva
Be sure to check out the previous articles in this series:
Efficiently retrieving knowledge in RAG systems is key to providing accurate and timely responses. Vector databases and indexing strategies play a crucial role in strengthening RAG systems’ performance. This article continues the Understanding RAG series by conceptualizing vector databases and indexing techniques commonly used in RAG systems. It aims to demystify their role, explain how they work, and explain why they are essential to most RAG systems.
What are Vector Databases?
Simply put, a vector database is a specialized type of database optimized for the storage and retrieval of text represented as high-dimensional vectors.
Why are these databases crucial for RAG? Because vector representations enable efficient similarity-based searches over large document bases, quickly retrieving relevant information based on a user query. In a vector database, semantically similar documents have closer vector representations.
For instance, the vectors associated with two Mediterranean restaurant reviews would be much more similar to each other than those associated with a Spanish restaurant review and a news article about classical music. Similarly, documents containing text that is semantically relevant to the user query will be retrieved efficiently through vector operations like dot products and cosine similarity.
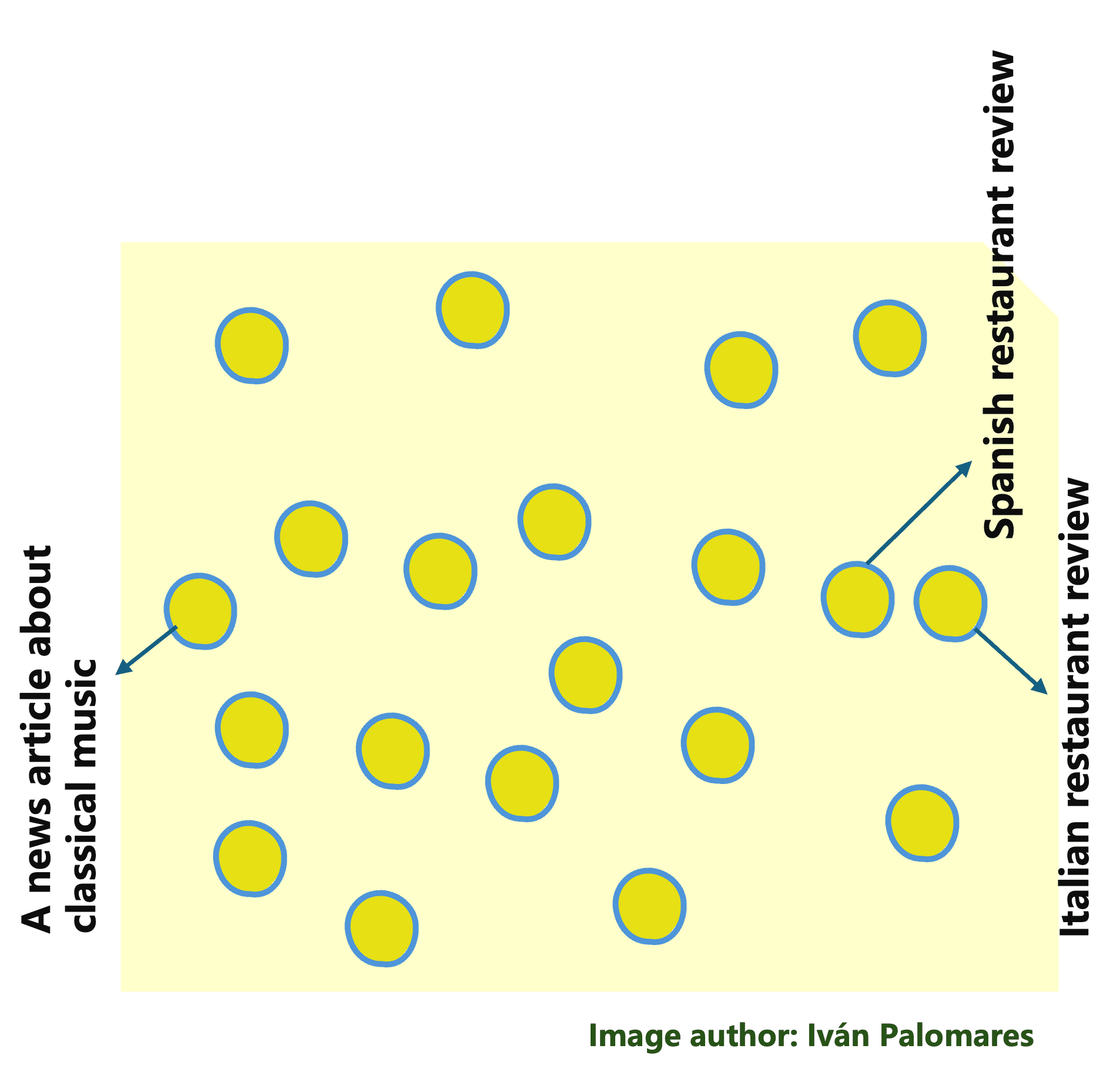
In a vector database, vector representations of semantically similar documents are close to each other.
It is important to understand the difference between vector databases and traditional databases. While traditional databases rely on structured data and exact matching, vector databases support unstructured retrieval, allowing for semantic searches rather than keyword-based lookups.
Overview and Impact of Indexing Strategies in RAG
The next question to answer is: how do RAG systems efficiently retrieve information from vector databases? The answer lies in indexing strategies, designed to speed up similarity searches while maintaining accuracy. Using an indexing strategy is like finding a book in a library by referencing a catalog instead of manually scanning every shelf.
The following are common indexing strategies implemented in RAG systems:
- Approximate Nearest Neighbors (ANN): A fast approach that significantly reduces search time, though it sacrifices some accuracy in favor of efficiency
- Hierarchical Navigable Small World (HNSW): A popular strategy that balances speed and accuracy by organizing data in a multi-layer graph structure for optimized nearest neighbor searches
- IVF (Inverted File Index): This strategy enhances large-scale search efficiency by splitting high-dimensional vectors into clusters, thereby turning the retrieval process faster when handling massive datasets
- PQ (Product Quantization): Used in advanced RAG systems, this method compresses vector data to reduce memory usage while enabling efficient similarity searches
A well-implemented indexing strategy combined with a solid vector database can impact the performance of RAG systems in multiple ways.
First, the accuracy and speed trade-off in retrieval gets optimized, guaranteeing that searches remain both efficient and relevant.
Second, indexing plays a central role in reducing latency without compromising the quality of responses generated by the RAG system. This in turn facilitates faster and more scalable knowledge retrieval.
Third, different RAG applications may benefit from distinct indexing strategies. For instance, real-time conversational AI assistants may prioritize HNSW indexing for quick yet accurate retrieval, whereas large-scale document search engines might lean towards IVF indexing to efficiently manage massive datasets.
Common Misconceptions
One common misconception is the belief that having more vectors in your database implies better retrieval. This is fundamentally false because retrieval quality depends on the relevance of vectors in the database and the effectiveness of the indexing strategy, rather than on the quantity of data stored. In fact, more vectors can yield increased noise, making it more difficult to retrieve truly relevant results efficiently.
Meanwhile, regarding indexing strategies, while a brute force like the exact nearest neighbor strategy — i.e. finding the most similar vector to the input query — might sound too slow to be useful, there are cases when it is preferable, for example when working with small datasets where exact nearest neighbor search provides maximum accuracy without significant performance loss.
It is also important to clarify that approximate searches do not inherently cause inaccuracies, but rather they can help significantly boost retrieval efficiency while keeping high-quality results through well-designed efficiency-precision trade-offs.
Wrapping Up
Understanding vector databases and indexing strategies is crucial for designing efficient and effective RAG systems. These two elements directly impact retrieval speed, accuracy, and RAG system performance. We outlined several indexing strategies and discussed some misconceptions about vector retrieval and certain search and indexing approaches.
The next post of this series will examine strategies to mitigate hallucinations in RAG systems: these are some of the biggest challenges in generating reliable responses in RAG systems and language models as a whole.