
Unlocking the potential of large multimodal language models (MLLMs) to handle diverse modalities like speech, text, image, and video is a crucial step in AI development. This capability is essential for applications such as natural language understanding, content recommendation, and multimodal information retrieval, enhancing the accuracy and robustness of AI systems.
Traditional methods for handling multimodal challenges often rely on dense models or single-expert modality approaches. Dense models involve all parameters in every computation, leading to increased computational overhead and reduced scalability as the model size grows. On the other hand, single-expert approaches lack the flexibility and adaptability required to effectively integrate and comprehend diverse multimodal data. These methods often struggle with complex tasks that involve multiple modalities simultaneously, such as understanding long speech segments or processing intricate image-text combinations.
The researchers from Harbin Institute of Technology have proposed the innovative Uni-MoE approach, which leverages a Mixture of Experts (MoE) architecture along with a strategic three-phase training strategy. Uni-MoE optimizes expert selection and collaboration, allowing modality-specific experts to work synergistically to enhance model performance. The three-phase training strategy includes specialized training phases for cross-modality data, which improves model stability, robustness, and adaptability. This new approach not only overcomes the drawbacks of dense models and single-expert approaches but also demonstrates significant advancements in the capabilities of multimodal AI systems, particularly in handling complex tasks that involve diverse modalities.
Uni-MoE’s technical advancements include a MoE framework specializing in different modalities and a three-phase training strategy for optimized collaboration. Advanced routing mechanisms allocate input data to relevant experts, optimizing computational resources, while auxiliary balancing loss techniques ensure equal expert importance during training. These intricacies make Uni-MoE a robust solution for complex multimodal tasks.
Results showcase Uni-MoE’s superiority with accuracy scores ranging from 62.76% to 66.46% across evaluation benchmarks like ActivityNet-QA, RACE-Audio, and A-OKVQA. It outperforms dense models, exhibits better generalization, and handles long speech understanding tasks effectively. Uni-MoE’s success marks a significant leap forward in multimodal learning, promising enhanced performance, efficiency, and generalization for future AI systems.
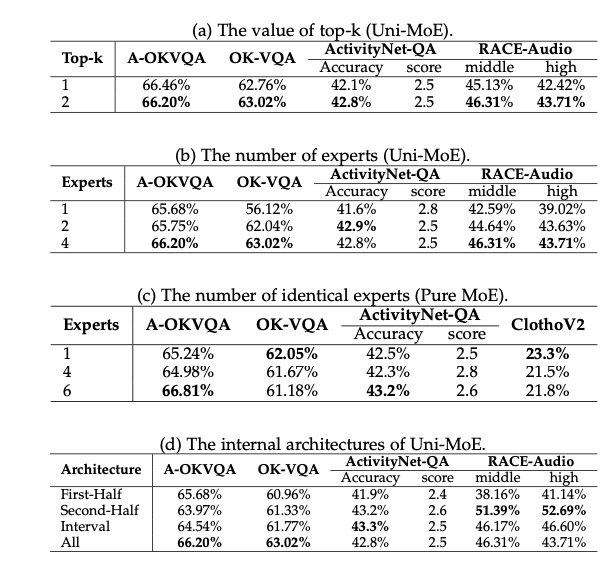
In conclusion, Uni-MoE represents a significant leap forward in the realm of multimodal learning and AI systems. Its innovative approach, leveraging a Mixture of Experts (MoE) architecture and a strategic three-phase training strategy, addresses the limitations of traditional methods and unlocks enhanced performance, efficiency, and generalization across diverse modalities. The impressive accuracy scores achieved on various evaluation benchmarks, including ActivityNet-QA, RACE-Audio, and A-OKVQA, underscore Uni-MoE’s superiority in handling complex tasks such as long speech understanding. This groundbreaking technology not only overcomes existing challenges but also paves the way for future advancements in multimodal AI systems, reaffirming its pivotal role in shaping the future of AI technology.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.