
Image by Author
Data is the lifeblood of data science and the backbone of the AI revolution. Without it, there are no models, and sophisticated algorithms are worthless because there is no data to bring their usefulness to life.
The web is known to be a contemporary powerhouse of data. Most data found on the web is generated due to the daily interactions of millions of users who contribute data to it knowingly or unknowingly. If properly collected and processed, the data found on the web could prove to be a goldmine, as we have seen the critical role it played in the case of OpenAI and many other breathtaking innovative technologies.
By following till the end of this article, you will learn what web scraping is, the tools used in web scraping, the importance of web scraping to the field of data science, and how to carry out a simple Data Scraping task on your own. If I were you, I’d stay glued!
Prerequisites
This article is intended for people with a working knowledge of Python, as the code snippets and libraries used in it are written in Python.
Also, basic knowledge of web HTML tags and attributes is needed to fully understand the code implementation in this article.
What is Web Scraping?
Web scraping is the process of extracting data from websites. It involves using software or scripts written in Python or any other compatible programming language to achieve this aim. The data extracted from web scraping is stored in a format and platform where it can be easily retrieved and used. For example, it could be stored as a CSV file or directly into a database for further use.
Tools Used for Web Scraping
There are several tools used for web scraping, but we’ll be limited to the ones compatible with Python. Listed below are some of the popular Python libraries used for web scraping:
- Beautifulsoup:
Used in web scraping for collecting data from HTML and XML files. It creates a parse tree for parsed website pages, which is useful for extracting data from HTML. It is easy to use and beginner-friendly. - Selenium:
Selenium is an open-source platform that houses a range of products. At its core is its browser automation capabilities, which simulate real user activities like filling forms, checking boxes, clicking links, and so on. It is also used for web scraping and can be implemented in many other languages apart from Python, such as Java, C Sharp, Javascript, and Ruby, to list a few. This makes it a very robust tool, even though it is not too beginner-friendly. Learn more about Selenium here. - Scrapy:
Scrapy is a web crawling and web scraping framework written in Python. It extracts structured data from website pages, and it can also be used for data mining and automated testing. Find more information about Scrapy here.
A Simple Guide on Web Scraping
For this article, we will use the beautifulsoup library. As an additional requirement, we will also install the requests library to make HTTP calls to the website from which we intend to scrape data.
For this practice exercise, we will scrape the website http://quotes.toscrape.com/, which was specifically made for such purposes. It contains quotes and their authors.
Let’s get started.
Step 1
Create a Python file for the project, such as webscraping.py
Step 2
In your terminal window, create and activate a virtual environment for the project and install the necessary libraries.
For Mac/Linux:
python3 -m venv venv
source venv/bin/activate
For Windows:
python3 -m venv venv
source venv\scripts\activate
Step 3
Install the necessary libraries
python3 -m venv venv
source venv\scripts\activate
This installs both the requests and beautifulsoup4 libraries to your already created virtual environment for this practice project.
Step 4
Open the webscraping.py you created earlier in step 1 and write the following code in it:
from bs4 import BeautifulSoup
import requests
The code above imports the requests module and the BeautifulSoup class, which we will be using subsequently.
Step 5
Now, we need to inspect the web page with our browser to determine how the data is contained in the HTML structure, tags, and attributes. This will enable us to easily target the right data to be scraped.
If you are using Chrome browser, open the website http://quotes.toscrape.com, right-click on the screen, and click on inspect. You should see something similar to these:
quotes.toscrape.com Website
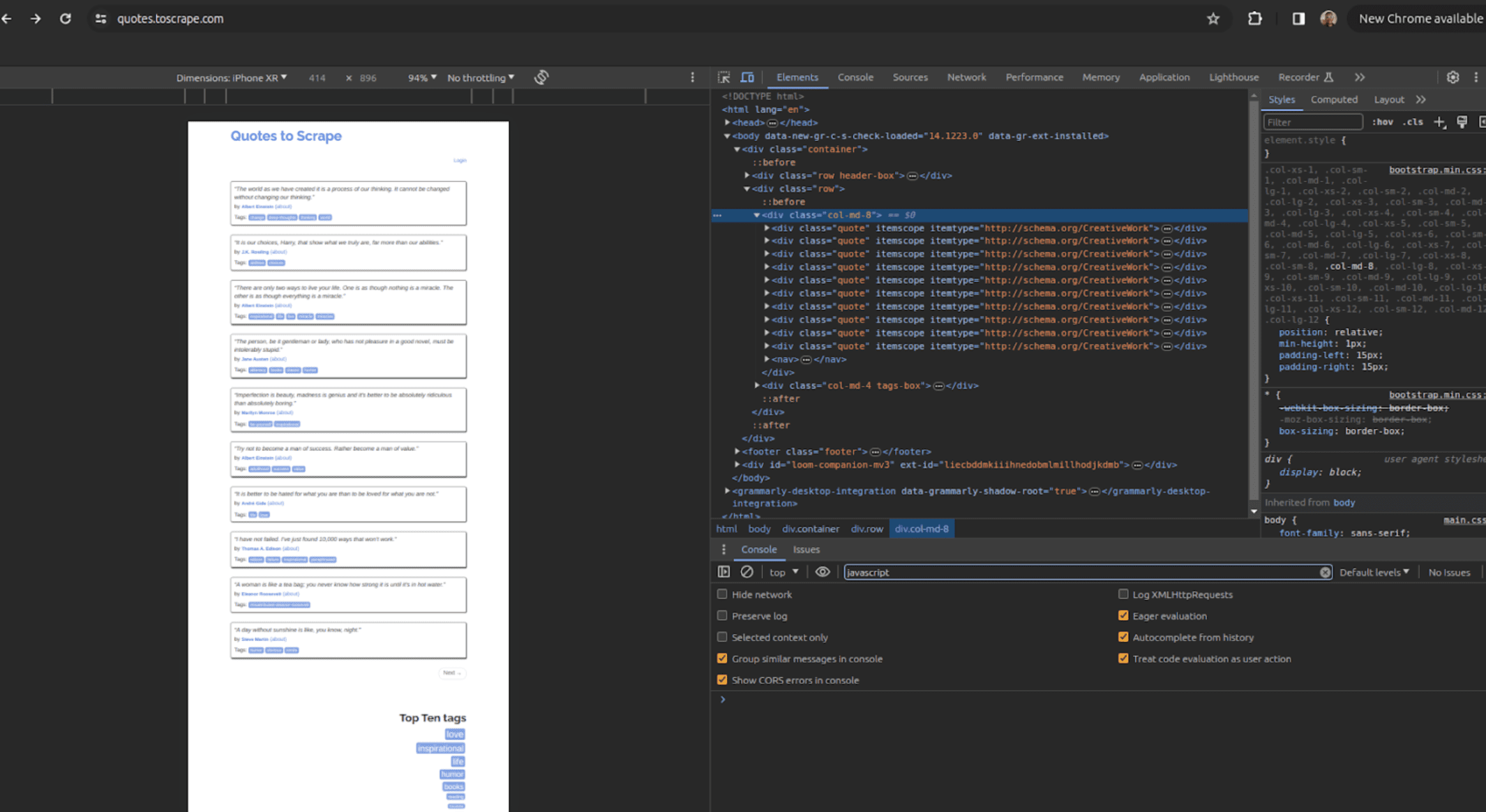
Now, you can see the various HTML tags and corresponding attributes for the elements containing the data we intend to scrape and note them down.
Step 6
Write the complete script into the file.
from bs4 import BeautifulSoup
import requests
import csv
# Making a GET request to the webpage to be scraped
page_response = requests.get("http://quotes.toscrape.com")
# Check if the GET request was successful before parsing the data
if page_response.status_code == 200:
soup = BeautifulSoup(page_response.text, "html.parser")
# Find all quote containers
quote_containers = soup.find_all("div", class_="quote")
# Lists to store quotes and authors
quotes = []
authors = []
# Loop through each quote container and extract the quote and author
for quote_div in quote_containers:
# Extract the quote text
quote = quote_div.find("span", class_="text").text
quotes.append(quote)
# Extract the author
author = quote_div.find("small", class_="author").text
authors.append(author)
# Combine quotes and authors into a list of tuples
data = list(zip(quotes, authors))
# Save the data to a CSV file
with open("quotes.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the header
writer.writerow(["Quote", "Author"])
# Write the data
writer.writerows(data)
print("Data saved to quotes.csv")
else:
print(f"Failed to retrieve the webpage. Status code: {page_response.status_code}")
The script above scrapes the http://quotes.toscrape.com website and also creates and saves a CSV file containing the authors and quotes obtained from the website, which can be used to train a machine learning model. Below is a brief explanation of the code implementation for ease of understanding:
- After importing the
BeautifulSoupclass,requests, andcsvmodule, as seen in lines 1, 2, and 3 of the script, we made a GET request to the webpage URLcsv(http://quotes.toscrape.com) and stored the response object returned in thepage_responsevariable. We checked if the GET request was successful by calling on thepage_responsepage_responseattribute on thepage_responsevariable before continuing the execution of the script - The
BeautifulSoupclass was used to create an object stored in thesoupvariable by taking the parsed HTML text content contained in thepage_responsevariable and theHTML.parseras constructor arguments. Note that theBeautifulSoupobject stored in thesoupvariable contains a tree-like data structure with several methods that can be used for accessing data in nodes down the tree, which, in this case, are nested HTML tags soupembodying the entire tree structure and data of the webpage was used to retrieve the parentdivcontainers in the page, from which the authors and quotes found in the respectivedivswere collected into a list and further transformed into a CSV file using the csv module and saved in thequotes.csvfile. If, unfortunately, the initial GET request to the website we scraped was unsuccessful due to network issues or something else, the message “failed to retrieve the webpage” with the appropriate status code will be printed or logged to the console
Conclusion
Knowing how to carry out web scraping on websites conveniently is an invaluable skill for Data Professionals.
So far, in this article, we have learned about web scraping and the popular Python libraries used for it. We have also written a Python script to scrape the http://quotes.toscrape.com website using the beautifulSoup library, thereby cementing our learning.
Always check the robot.txt file of any website before you scrape it, and make sure it is allowed to do so.
Thanks for reading, and happy scraping!
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.