

Image by Author | Canva & DALL-E
Who here hasn’t heard of ChatGPT? Even if you haven’t personally used it, you must have heard it from some of your friends or acquaintances. Its ability to carry out conversations in a natural tone and perform tasks as directed makes it one of the best revolutions in AI. Before moving on, it’s very important to discuss:
What are LLMs?
Large Language models are an advancement of artificial intelligence that can predict and generate human-like text. LLMs are called “large” because they are several gigabytes in size and have billions of parameters that help them understand and generate language. By learning the structure, grammar, and meaning of language, these models can perform tasks like answering questions, summarizing content, and even creating creative stories. They’re trained on huge amounts of text—think books, websites, and more—which helps them learn all kinds of patterns and contexts. This process requires a lot of computing power, which is why they are costly to build.
In this article, I will discuss how LLMs work and how you can easily get started with them.
How Do LLMs Work?
LLMs use deep learning techniques, particularly neural networks, to process and understand language. Let’s discuss the working of LLMs by breaking it down into steps:
1. Transformer Architecture
The most popular LLMs, like OpenAI’s GPT (Generative Pre-trained Transformer) series, use a transformer architecture to process massive datasets. The transformer architecture processes sequences in parallel and captures dependencies between words using attention mechanisms. The main components that play an important in the working of a transformer are:
- A. Self-Attention Mechanism: This allows the model to focus on relevant parts of a sentence or context while processing input. For every word, the model computes how strongly it relates to every other word in the input sequence.
Example: In the sentence “The girl found her book on the table,” the model calculates that “her” refers to “girl,” as their relationship is stronger than “her” and “book.”
- B. Positional Encoding: Since transformers process data in parallel (not sequentially), positional encoding adds information about word order.
Example: In the sentence “He read the book before going to bed,” positional encoding helps the model recognize that “before” connects “read” and “going to bed,” keeping the chronological order intact.
- C. Feedforward Neural Networks:After attention is applied, data flows through dense layers to transform and extract patterns from the input.
Example: In the sentence “The teacher explained the lesson clearly,” the neural network may recognize the pattern where “teacher” is related to actions like “explained,” and understand that “lesson” is the object being explained.
The following figure explains working of a transformer in a simplified way:

Transformer Architecture — Simplified [Source: Hitchhikers guide to LLMs]
These components enable transformers to understand relationships between words, phrases, and their contexts, generating highly coherent text.
2. Training Of LLMs
LLMs are trained in two stages: Pre-training and Fine-tuning. The following figure shows how LLMs are trained:

Stages of LLM from pre-training to prompting [Source: A Comprehensive Overview of Large Language Models]
To understand the figure clearly, let’s discuss the stages one by one:
- A. Pre-training: The model is trained on general-purpose text data to learn language patterns and structures. It is trained on vast amounts of text from diverse sources, such as books, articles, websites, and conversations. The training process involves:
- Tokenization: This process is already explained in the diagram of the working of transformers. It basically means to divide the text into smaller units called tokens. These can be words, subwords, or even individual characters.
Example: The sentence “I want to swim,” might be tokenized as [“I”, “want”, “to”, ”swim”].
- Masked Language Modeling (MLM): During training, some tokens are hidden, and the model predicts them based on the surrounding context. This teaches the model to understand language structure and meaning.
Example: For the sentence “The ___ is blue,” the model might predict “sky” based on surrounding words. This teaches the model to infer missing information.
- Next-Token Prediction: The model learns to predict the next token in a sequence, enabling it to generate text.
Example: Given the input “The sky is,” the model predicts “blue” as the most likely continuation.
The following figure explains pre training in a simplified way:

Simplified Pre-training in LLMs [Source: Hitchhikers guide to LLMs]
At this stage, the model develops a broad understanding of language but lacks task-specific knowledge.Example: The model understands that “Water boils at 100 degrees Celsius” or “Apples are a type of fruit,” but it lacks task-specific skills like summarizing articles or translating text.
- Tokenization: This process is already explained in the diagram of the working of transformers. It basically means to divide the text into smaller units called tokens. These can be words, subwords, or even individual characters.
- B. Fine-tuning: After pre-training, the model understands the language and can generate next tokens but lacks specific task related knowledge. Fine-tuning is necessary to make a pretrained model more suited to particular tasks. It improves the accuracy of the model and also helps shape the model’s behavior to match what humans expect and find useful.
Example: A model trained on fitness data will provide personalized workout plans, while one trained on customer support data will handle helpdesk queries.
The following figure explains and clarifies the purpose of effectively pre-training and fine-tuning.
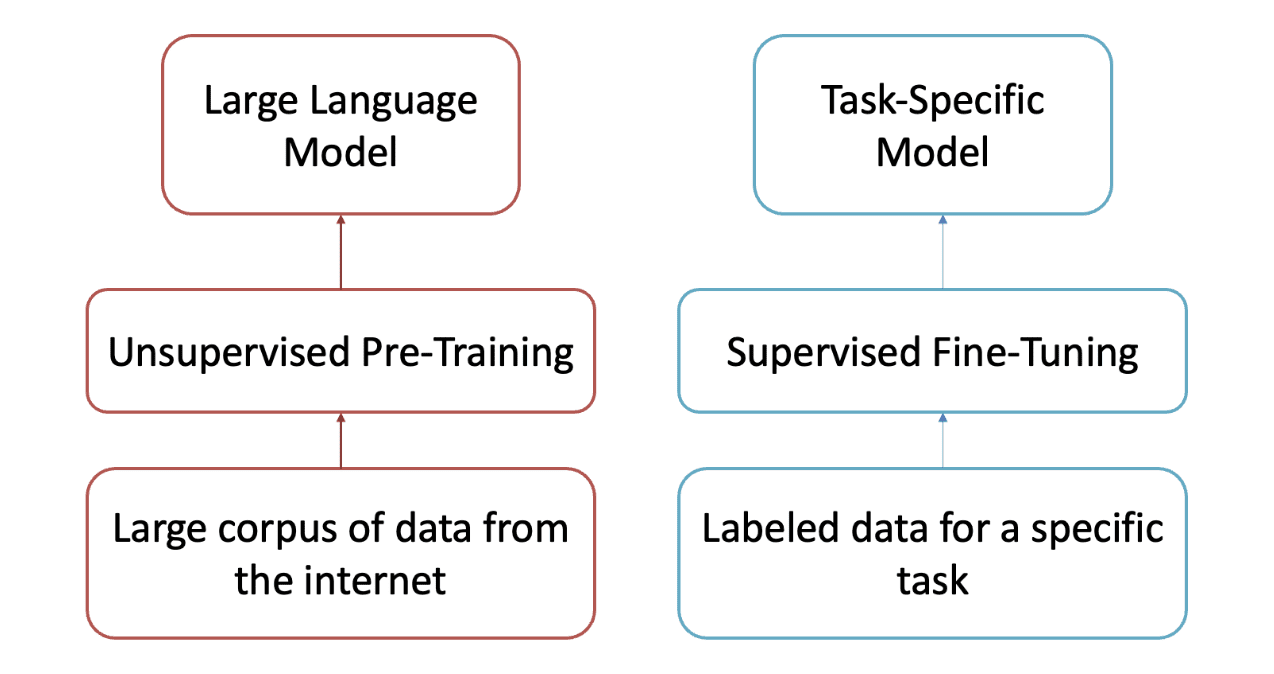
Source: DLL Lab TUKL
- C. Reinforcement Learning with Human Feedback: The fine-tuned model is then subjected to Reinforcement Learning with Human Feedback (RLHF). It helps LLMs give better, human-aligned responses by following two steps:
- Reward Modeling: A reward model is trained using human-labeled rankings of LLM responses based on quality criteria (e.g., helpfulness, honesty). The model learns to rank responses as preferred or non-preferred.
- Reinforcement Learning: Using the reward model, the LLM is adjusted to prioritize preferred responses over less desirable ones. This process is repeated until the model consistently aligns with human preferences.
Now, you pretty much understand the figure except for prompting. Let’s discuss it in detail.
3. Prompting
In LLMs, the act of providing input to the model to guide it in generating the desired output. It’s how users interact with the model to ask questions, request information, or generate text. The model’s response relies on how the prompt is phrased. There are different types of prompting:
- A. Zero-Shot Prompting: The model is asked to perform a task without any prior examples.
Example: “Explain how photosynthesis works.” - B. Few-Shot Prompting: The model is given a few examples to help it understand the task better.
Example: “Translate English to French: ‘Hello’ -> ‘Bonjour’. ‘Goodbye’ -> ‘Au revoir’. ‘Please’ -> ? - C. Instruction Prompting: The model is given a clear instruction to follow.
Example: “Write a letter to a friend inviting them to your birthday party.”
The way a prompt is constructed can greatly impact the quality and relevance of the model’s response.
4. Response Generation by LLMs
- A. Inference & Token-by-Token Generation: When generating responses, LLMs work step-by-step:
- Input Encoding:
The input text is converted into tokens and passed through transformer layers.
Example: The question “What is the capital of Japan?” might be tokenized into [“What”, “is”, “the”, “capital”, “of”, “Japan”, “?”]. - Probability Distribution:
The model predicts probabilities for the next token based on the current context.
Example: For “capital of,” the model might assign probabilities to likely continuations:
Tokyo: 90%
Kyoto: 5%
Osaka: 5%. - Token Selection:
The most likely token (“Tokyo”) is selected and added to the output. - Iteration:
Steps 2–3 repeat until the response is complete.
Example: Starting with “The capital of Japan is,” the model generates “The capital of Japan is Tokyo.”
This token-by-token approach ensures smooth, logical responses. One interesting thing to know here is that LLMs generate coherent responses. Let’s discuss this in a bit more detail.
- Input Encoding:
- B. Coherent Responses/ Contextual Understanding: LLMs excel at contextual understanding, meaning they analyze entire sentences, paragraphs, or even documents to generate coherent responses.
Example: If asked, “What is the capital of France, and why is it famous?” the model recognizes that the answer involves two parts:
- Capital: Paris
- Why it’s famous: Known for landmarks like the Eiffel Tower, rich history, and cultural influence.
This contextual awareness enables the model to generate precise, multi-faceted answers.
Strengths & Applications of LLMs
LLMs (Large Language Models) offer impressive strengths such as natural language understanding, contextual learning, logical reasoning, and multitasking. LLMs also support continuous learning and adaptation based on feedback. These strengths make LLMs highly applicable in various fields such as:
- Content Creation: Writing articles, blogs, and social media posts.
- Virtual Assistants: Powering AI assistants like Siri and Alexa.
- Search Engines: Enhancing query understanding and result relevance.
- Data Analytics: Deriving meaningful insights that can help make decisions.
- Code Development: Helping to write simple or complex code, developing test cases, and fixing bugs.
- Scientific Research: Summarizing research papers and generating hypotheses.
- Sentiment Analysis: Analyzing customer feedback and social media trends.
These are just a few of the many applications of LLMs, and their range of applications will only grow in the future.
Drawbacks Of LLMs
Having many strengths, Large language models also have some shortcomings which are:
- Hallucinations & Misinformation: LLMs often produce responses that sound reasonable but are factually incorrect, which can lead to misinformation if not fact-checked
- Contextual limitations: LLMs can have trouble keeping track of context in long conversations or large texts, which can lead to responses that feel disconnected or off-topic.
- Privacy concerns: LLMs can unintentionally generate sensitive or private information from their training data leading to privacy concerns.
- Reliance on Large Data Sets & High Computational Power: LLMs depend on massive amounts of data and significant computational power for training, which makes them highly demanding and costly to develop.
- Data Dependency & Bias in LLM Responses: LLMs can produce biased content based on their training data, which can include stereotypes and unfaired assumptions. For instance, they might assume that wrestlers are always male or that only women should work in the kitchen.
Conclusion
To wrap up, this article provides a detailed introduction to large language models, their applications, working, strengths, and shortcomings. By 2025, LLMs are becoming more integrated into everyday life and are overcoming many of their shortcomings. 2025 may be the best year for you to start learning LLMs, as its market is expected to grow exponentially in the near future. I have written a whole article about the courses and other material that you should cover while learning large language models. You can go to this article and start your learning journey.
Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.