
Image by Editor | Midjourney
Introducing the Transformer
The transformer. Is it a deep learning architecture? Is it an advanced natural language processing (NLP) solution? Is it what ChatGPT’s powerful models look like from the inside? A transformer actually has a lot to do with all of these questions.
Until recently, traditional NLP tasks like text translation and sentiment analysis were often addressed by training deep learning models such as recurrent neural networks, which process text sequences one step at a time. While these architectures achieved some success in modeling sequential data, they also came with important limitations. For instance, when analyzing longer pieces of text, they struggle with long-range dependencies — in other words, they have a hard time remembering words that appeared earlier and often fail to capture relationships between distant parts of a sentence or paragraph. Additionally, their purely sequential nature makes them slow and inefficient when processing long sequences.
Transformers emerged toward the end of the last decade as a revolutionary architecture designed to overcome these limitations — and they didn’t disappoint.
In this article, we’ll explore what a transformer is, how it originated, why it became so successful that it powered some of the most groundbreaking AI advances — including large language models (LLMs) — and what applications it has within and beyond NLP.
Depicting the Transformer
A transformer is a deep learning-based architecture that combines effective pattern recognition in unstructured data like text with the ability to understand and generate human language. It was originally designed to handle sequence-to-sequence tasks that involve both language understanding and generation — for instance, translating text from one language to another and summarizing long articles.
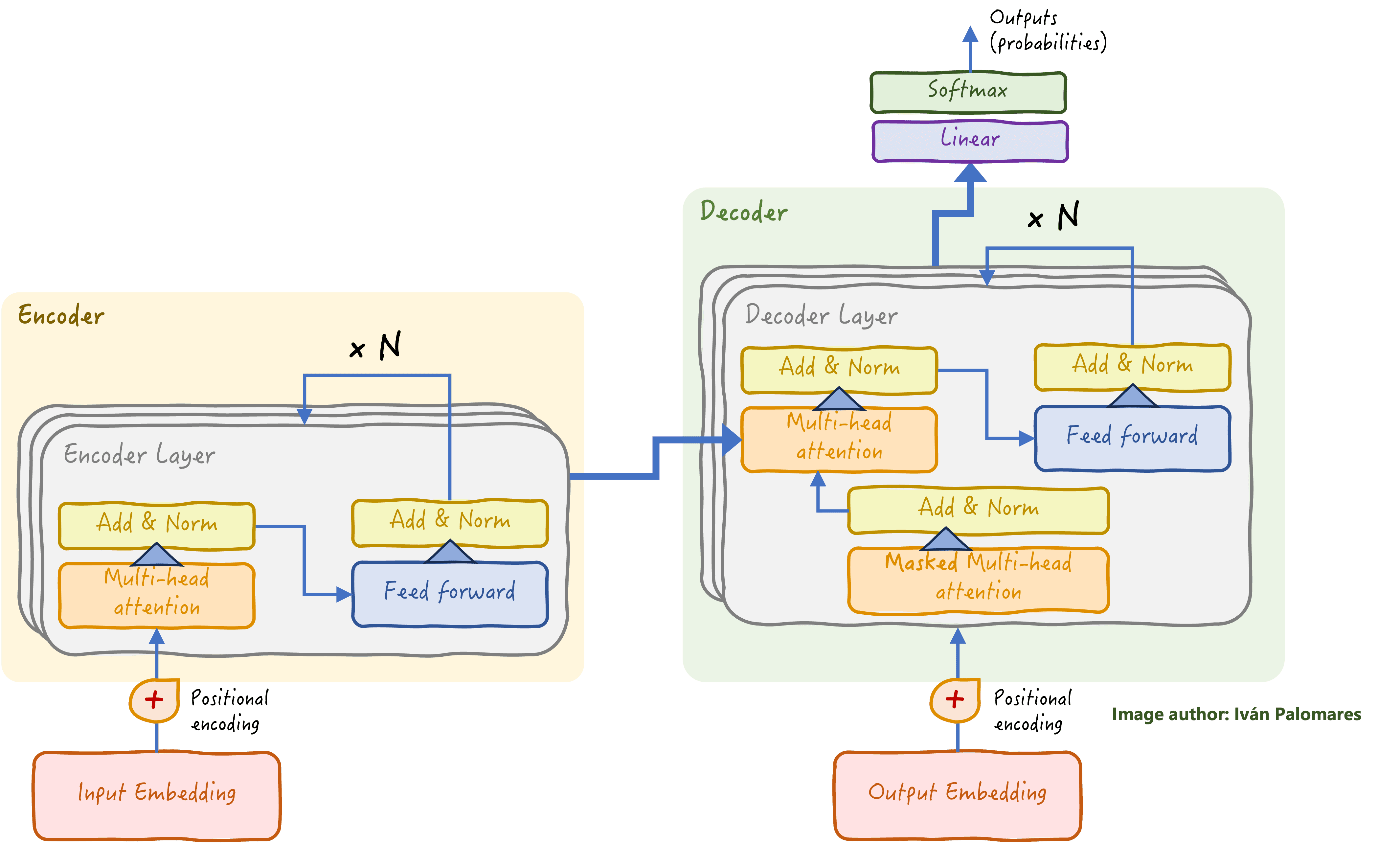
Overview of the transformer architecture | Image by Author
The transformer architecture is roughly divided into two main blocks: the encoder and the decoder.
- The encoder is responsible for analyzing and understanding the input text. The encoder block is actually made up of multiple identical subunits that are replicated, each containing layers of neurons and other specialized components that we’ll explain shortly, through which the data flows sequentially. As a result of a lot of intricate computations, the transformer gradually builds a deep, layered understanding of the text and its nuances, be it syntactic, semantic, or even contextual, such as tone, intent, or changes in topic.
- Meanwhile, the decoder focuses on generating the appropriate output for the task at hand — for example, a translation of the original text into another language — based on the understanding gained after having passed the input information through the encoder.
What makes transformers especially effective at addressing complex NLP tasks at a previously-unprecedented level is their use of a component called the attention mechanism (see multi-head attention blocks in the diagram above). Attention mechanisms — or, more specifically, their advanced form known as multi-head attention — give the transformer model the ability to capture relationships and weigh the importance of such relationships between different words and parts of a sentence, regardless of their position. By having a multi-head attention mechanism, the transformer has each “attention head” specialize in capturing a specific aspect of the language: syntax, semantics, and so on. This is similar to how we, as humans, can focus on the key elements of a sentence to capture its exact meaning by connecting pieces of language that may show up far apart from each other.
The attention mechanism is also placed in the decoder part and goes one step further by capturing interrelationships between the input elements and the output being generated word by word. The example in the illustration below illustrates this principle: the attention mechanism identifies the words “like” and “travel” as the most relevant ones to infer what word should go next in the output sequence consisting of a Spanish translation. Note that gray levels depicted in the image below the input words indicate the strength of the relationship with the output.
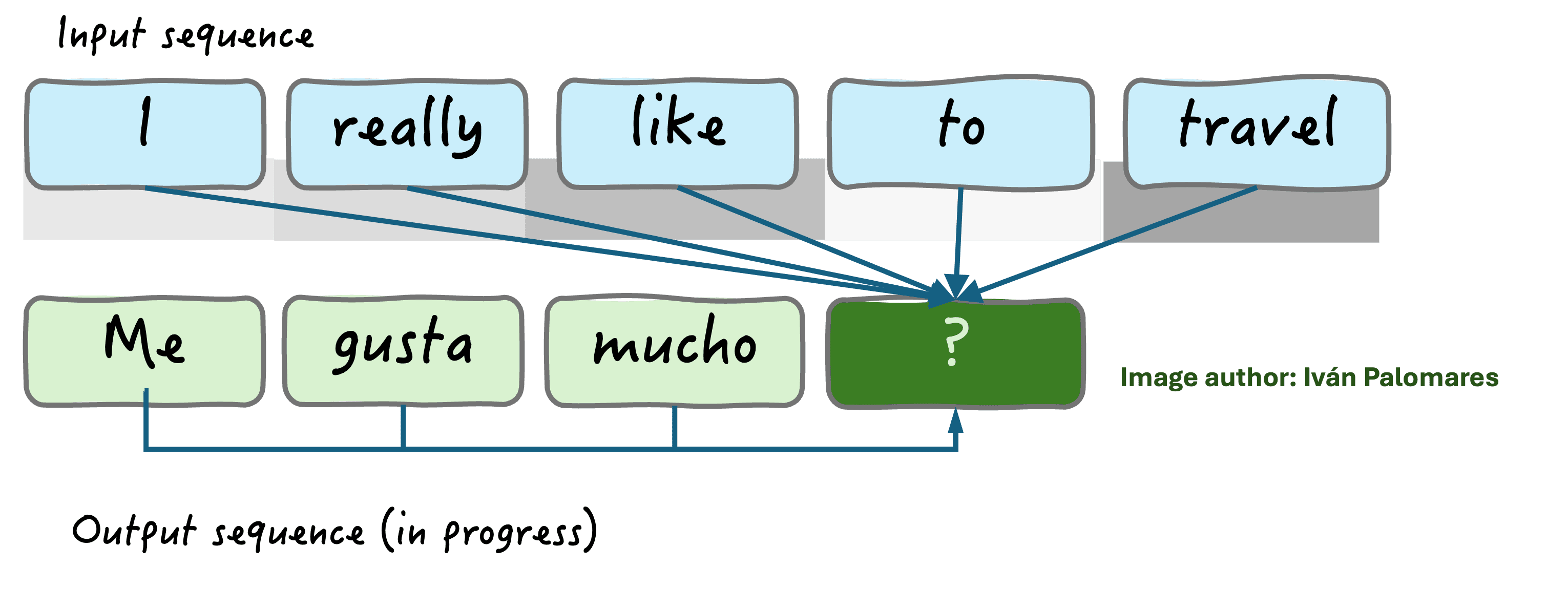
The attention mechanism captures and weighs dependencies between parts of the language | Image by Author
Transformers in the Real World: Applications in NLP and Beyond
No doubt, the transformer architecture has revolutionized the entire AI and machine learning landscape, largely shaping its direction of progress over the last few years. Some of the most ground-breaking advances brought by this architecture include LLMs such as GPT, BERT, and T5, which have dramatically improved the ability of machines to understand and generate human language and even fuel powerful conversational AI solutions like ChatGPT and Claude.
Real-world applications of transformers range from AI-powered chatbots and real-time translation tools to smarter search engines that integrate LLMs into complex retrieval systems called RAG, grammar correction, content summarization, and creative writing.
However, transformers are not only suitable for handling complex NLP tasks. They have also proved effective in other domains like computer vision, where they are used to recognize patterns in image and video data. They have also proven their worth in biology for tasks such as protein structure prediction. This adaptability across different types of data and tasks is part of what makes the transformer architecture so powerful and far-reaching.
Nonetheless, they have limitations in some scenarios where conventional machine learning models remain more suitable — for instance, when working with small, structured datasets for classification and regression problems of a predictive nature — or when model interpretability is a priority.
Wrapping Up
Transformers have completely reshaped the AI landscape by overcoming traditional models’ limitations and powering breakthroughs in everything from language processing to computer vision. Their multi-head attention mechanism allows them to capture subtle, long-range dependencies, making them adept at understanding and generating complex data.
When it comes to turning complexity into clarity, transformers really know how to change the game.
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.