

Image created by Author
Introduction
An important step in generating predictive models is selecting the correct machine learning algorithm to use, a choice which can have a seemingly out-sized effect on model performance and efficiency. This selection can even determine the success of the most basic of predictive tasks: whether a model is able to sufficiently learn from training data and generalize to new sets of data. This is especially important for data science practitioners and students, who face an overwhelming number of potential choices as to which algorithm to run with. The goal of this article is to help demystify the process of selecting the proper machine learning algorithm, concentrating on “traditional” algorithms and offering some guidelines for choosing the best one for your application.
The Importance of Algorithm Selection
The choice of a best, correct, or even sufficient algorithm can dramatically improve a model’s ability to predict accurately. The wrong choice of algorithm, as you might be able to guess, can lead to suboptimal model performance, perhaps not even reaching the threshold of being useful. This results in a substantial potential advantage: selecting the “right” algorithm which matches the statistics of the data and problem will allow a model to learn well and provide outputs more accurately, possibly in less time. Conversely, picking the incorrect algorithm can have a wide range of negative consequences: training times might be longer; training might be more computationally expensive; and, worst of all, the model could be less reliable. This could mean a less accurate model, poor results when given new data, or no actual insights into what the data can tell you. Doing poorly on any or all of these metrics can ultimately be a waste of resources and can limit the success of the entire project.
tl;dr Correctly choosing the right algorithm for the task directly influences machine learning model efficiency and accuracy.
Algorithm Selection Considerations
Choosing the right machine learning algorithm for a task involves a variety of factors, each of which is able to have a significant impact on the eventual decision. What follows are several facets to keep in mind during the decision-making process.
Dataset Characteristics
The characteristics of the dataset are of the utmost importance to algorithm selection. Factors such as the size of the dataset, the type of data elements contained, whether the data is structured or unstructured, are all top-level factors. Imagine employing an algorithm for structured data to an unstructured data problem. You probably won’t get very far! Large datasets would need scalable algorithms, while smaller ones may do fine with simpler models. And don’t forget the quality of the data — is it clean, or noisy, or maybe incomplete — owing to the fact that different algorithms have different capabilities and robustness when it comes to missing data and noise.
Problem Type
The type of problem you are trying to solve, whether classification, regression, clustering, or something else, obviously impacts the selection of an algorithm. There are particular algorithms that are best suited for each class of problem, and there are many algorithms that simply do not work for other problem types whatsoever. If you were working on a classification problem, for example, you might be choosing between logistic regression and support vector machines, while a clustering problem might lead you to using k-means. You likely would not start with a decision tree classification algorithm in an attempt to solve a regression problem.
Performance Metrics
What are the ways you intend to capture for measuring your model’s performance? If you are set on particular metrics — for instance, precision or recall for your classification problem, or mean squared error for your regression problem — you must ensure that the selected algorithm can accommodate. And don’t overlook additional non-traditional metrics such as training time and model interpretability. Though some models might train more quickly, they may do so at the cost of accuracy or interpretability.
Resource Availability
Finally, the resources you have available at your disposal may greatly influence your algorithm decision. For example, deep learning models might require a good deal of computational power (e.g., GPUs) and memory, making them less than ideal in some resource-constrained environments. Knowing what resources are available to you can help you make a decision that can help make tradeoffs between what you need, what you have, and getting the job done.
By thoughtfully considering these factors, a good choice of algorithm can be made which not only performs well, but aligns well with the objectives and restrictions of the project.
Beginner’s Guide to Algorithm Selection
Below is a flowchart that can be used as a practical tool in guiding the selection of a machine learning algorithm, detailing the steps that need to be taken from the problem definition stage through to the completed deployment of a model. By adhering to this structured sequence of choice points and considerations, a user can successfully evaluate factors that will play a part in selecting the correct algorithm for their needs.
Decision Points to Consider
The flowchart identifies a number of specific decision points, much of which has been covered above:
- Determine Data Type: Understanding whether data is in structured or unstructured form can help direct the starting point for choosing an algorithm, as can identifying the individual data element types (integer, Boolean, text, floating point decimal, etc.)
- Data Size: The size of a dataset plays a significant role in deciding whether a more straightforward or more complex model is relevant, depending on factors like data size, computational efficiency, and training time
- Type of Problem: Precisely what kind of machine learning problem is being tackled — classification, regression, clustering, or other — will dictate what set of algorithms might be relevant for consideration, with each group offering an algorithm or algorithms that would be suited to the choices made about the problem thus far
- Refinement and Evaluation: The model which results form the selected algorithm will generally proceed from choice, through to parameter finetuning, and then finish in evaluation, with each step being required to determine algorithm effectiveness, and which, at any point, may lead to the decision to select another algorithm
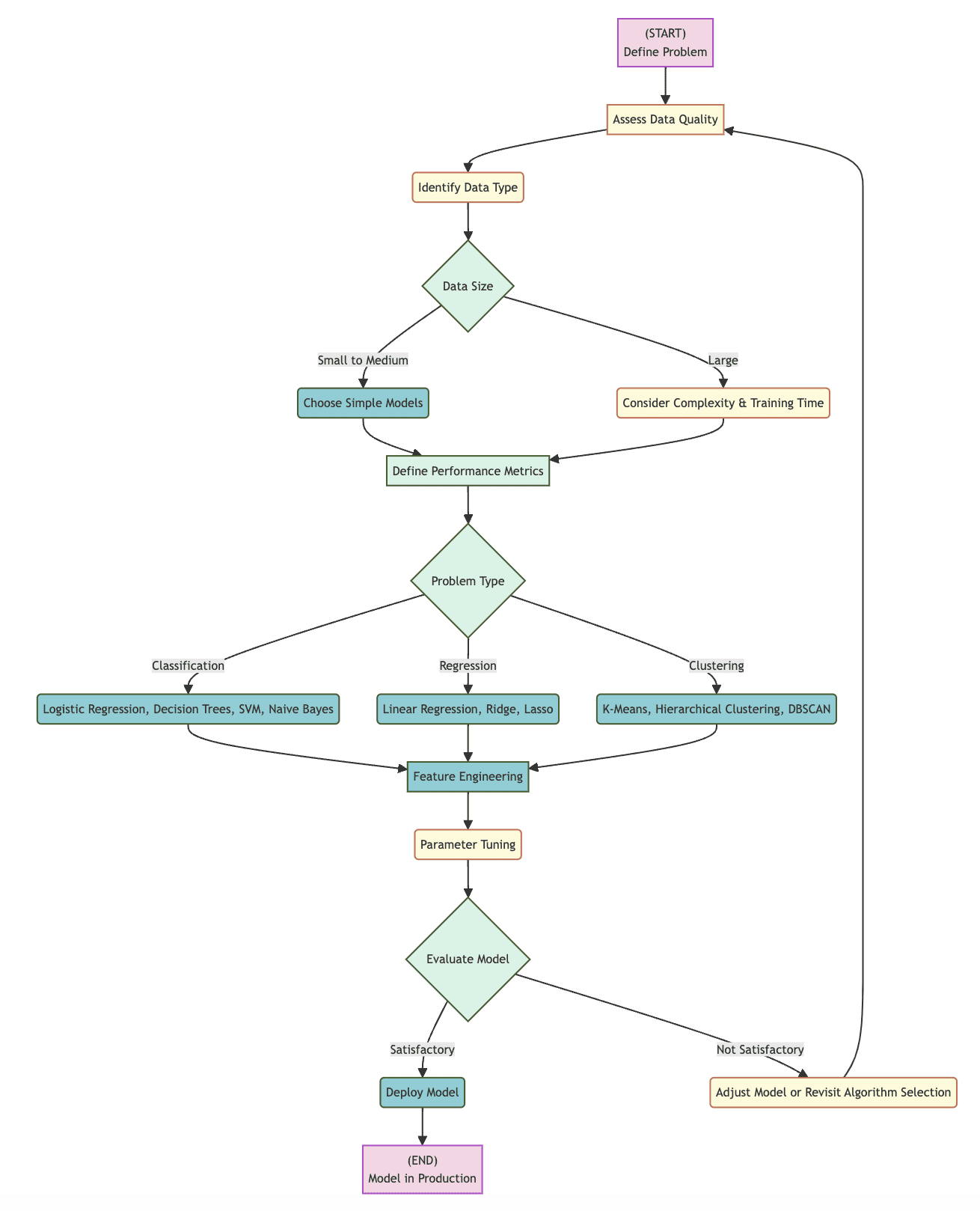
Flowchart visualization created by Author (click to enlarge)
Taking it Step by Step
From start to finish, the above flowchart outlines an evolution from problem definition, through data type identification, data size assessment, problem categorization, to model choice, refinement, and subsequent evaluation. If the evaluation indicates that the model is satisfactory, deployment might proceed; if not, an alteration to the model or a new attempt with a different algorithm may be necessary. By rendering the algorithm selection steps more straightforward, it is more likely that the most effective algorithm will be selected for a given set of data and project specifications.
Step 1: Define the Problem and Assess Data Characteristics
The foundations of selecting an algorithm reside in the precise definition of your problem: what you want to model and which challenges you’re trying to overcome. Concurrently, assess the properties of your data, such as the data’s type (structured/unstructured), quantity, quality (absence of noise and missing values), and variety. These collectively have a strong influence on both the level of complexity of the models you’ll be able to apply and the kinds of models you must employ.
Step 2: Choose Appropriate Algorithm Based on Data and Problem Type
The following step, once your problem and data characteristics are laid bare beforehand, is to select an algorithm or group of algorithms most suitable for your data and problem types. For example, algorithms such as Logistic Regression, Decision Trees, and SVM might prove useful for binary classification of structured data. Regression may indicate the use of Linear Regression or ensemble methods. Cluster analysis of unstructured data may warrant the use of K-Means, DBSCAN, or other algorithms of the type. The algorithm you select must be able to tackle your data effectively, while satisfying the requirements of your project.
Step 3: Consider Model Performance Requirements
The performance demands of differing projects require different strategies. This round involves the identification of the performance metrics most important to your enterprise: accuracy, precision, recall, execution speed, interpretability, and others. For instance, in vocations when understanding the model’s inner workings is crucial, such as finance or medicine, interpretability becomes a critical point. This data on what characteristics are important to your project must in turn be broadsided with the known strengths of varying algorithms to ensure they are met. Ultimately, this alignment ensures that the needs of both data and business are met.
Step 4: Put Together a Baseline Model
Instead of striking out for the bleeding edge of algorithmic complexity, begin your modeling with a straightforward initial model. It should be easy to install and fast to run, presented the estimation of performance of more complex models. This step is significant for establishing an early-model estimate of potential performance, and may point out large-scale issues with the preparation of data, or naïve assumptions that were made at the outset.
Step 5: Refine and Iterate Based on Model Evaluation
Once the baseline has been reached, refine your model based on performance criteria. This involves tweaking model’s hyperparameters and feature engineering, or considering a different baseline if the previous model doesn’t fit the performance metrics specified by the project. Iteration through these refinements can happen multiple times, and each tweak in the model can bring with it increased understanding and better performance. Refinement and evaluating the model in this way is the key to optimizing its performance at meeting the standards set.
This level of planning not only cuts down on the complex process of selecting the appropriate algorithm, but will also increase the likelihood that a durable, well-placed machine learning model can be brought to bear.
The Result: Common Machine Learning Algorithms
This section offers an overview of some commonly used algorithms for classification, regression, and clustering tasks. Knowing these algorithms, and when to use them as guided, can help individuals make decisions associated with their projects.
Common Classification Algorithms
- Logistic Regression: Best used for binary classification tasks, logistic regression is a an effective but simple algorithm when the relationship between dependent and independent variables is linear
- Decision Trees: Suitable for multi-class and binary classification, decision tree models are straightforward to understand and use, are useful in cases where transparency is important, and can work on both categorical and numerical data
- Support Vector Machine (SVM): Great for classifying complex problems with a clear boundary between classes in high-dimensional spaces
- Naive Bayes: Based upon Bayes’ Theorem, works well with large data sets and is often fast relative to more complex models, especially when data is independent
Common Regression Algorithms
- Linear Regression: The most basic regression model in use, most effective when dealing with data that can be linearly separated with minimal multicollinearity
- Ridge Regression: Adds regularization to linear regression, designed to reduce complexity and prevent overfitting when dealing with highly correlated data
- Lasso Regression: Like Ridge, also includes regularization, but enforces model simplicity by zeroing out the coefficients of less influential variables
Common Clustering Algorithms
- k-means Clustering: When the number of clusters and their clear, non-hierarchical separation are apparent, use this simple clustering algorithm
- Hierarchical Clustering: Let Hierarchical Clustering facilitate the process of discovering and accessing deeper clusters along the way, if your model requires hierarchy
- DBSCAN: Consider implementing DBSCAN alongside your dataset if the goal is to find variable-shaped clusters, flag off visible and far-from clusters in your dataset, or work with highly noisy data as a general rule
Keeping performance objectives in mind, your choice of algorithm can be suited to the characteristics and goals of your dataset as outlined:
- In situations where the data are on the smaller side and the geography of classes are well understood such that they may easily be distinguished, the implementation of simple models — such as Logistic Regression for classification and Linear Regression for regression — is a good idea
- To operate on large datasets or prevent overfitting in modeling your data, you’ll want to consider focusing on more complicated models such as Ridge and Lasso regression for regression problems, and SVM for classification tasks
- For clustering purposes, if you are faced with a variety of concerns such as recovering basic mouse-click clusters, identifying more intricate top-down or bottom-up hierarchies, or working with especially noisy data, k-means, Hierarchical Clustering, and DBSCAN should be looked into for these considerations as well, dependent on the dataset particulars
Summary
The selection of a machine learning algorithm is integral to the success of any data science project, and an art itself. The logical progression of many steps in this algorithm selection process are discussed throughout this article, concluding with a final integration and the possible furthering of the model. Every step is just as important as the previous, as each step has an impact on the model that it guides. One resource developed in this article is a simple flow chart to help guide the choice. The idea is to use this as a template for determining models, at least at the outset. This will serve as a foundation to build upon in the future, and offer a roadmap to future attempts at building machine learning models.
This basic point holds true: the more that you learn and explore different methods, the better you will become at using these methods to solve problems and model data. This requires you to continue questioning the internals of the algorithms themselves, as well as to stay open and receptive to new trends and even algorithms in the field. In order to be a great data scientist, you need to keep learning and remain flexible.
Remember that it can be a fun and rewarding experience to get your hands dirty with a variety of algorithms and test them out. By following the guidelines introduced in this discussion you can come to comprehend the aspects of machine learning and data analysis that are covered here, and be prepared to address issues that present themselves in the future. Machine learning and data science will undoubtedly present numerous challenges, but at some point these challenges become experience points that will help propel you to success.
Matthew Mayo (@mattmayo13) holds a Master’s degree in computer science and a graduate diploma in data mining. As Managing Editor, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.