
This study’s research area is artificial intelligence (AI) and machine learning, specifically focusing on neural networks that can understand binary code. The aim is to automate reverse engineering processes by training AI to understand binaries and provide English descriptions. This is important because binaries can be challenging to comprehend due to their complexity and lack of transparency. Malware analysis and reverse engineering tasks are particularly demanding, and the scarcity of experienced professionals further accentuates the need for efficient automated solutions.
The research addresses a significant problem: understanding what binary code does is difficult because it requires specialized skills and knowledge. Often, reverse engineers have to delve deep into the code to discern its functionality. The research team aimed to simplify this process by building an automated tool to analyze the code and generate meaningful English descriptions, helping security experts understand a piece of software, whether malicious or benign. This tool could save time and provide clarity when traditional methods struggle.
Current approaches involve large language models (LLMs) and datasets that link code to English descriptions. However, the datasets in use have notable shortcomings, such as insufficient samples, vague descriptions, or a focus on interpreted languages instead of compiled ones. For instance, datasets like XLCoST and GitHub-Code have limitations in providing accurate code descriptions. In contrast, others like Deepcom-Java and CoNaLa lack coverage for widely used compiled languages like C and C++.
The researchers from MIT Lincoln Laboratory, Lexington, MA, USA, introduced a new dataset from Stack Overflow, one of the largest online programming communities. With over 1.1 million entries, this dataset was intended to translate binaries into English descriptions better. The team designed a method to extract data from this vast resource, transforming it into a structured dataset that pairs binaries with textual descriptions. This dataset became a substantial source of information for training machine learning models.
The researchers’ approach involved parsing Stack Overflow pages tagged with C or C++ and converting them into snippets. These snippets contained code and textual explanations, which were processed to extract the most relevant information. The team then generated compilable binaries from this data and matched them with the appropriate text explanations, creating a dataset of 73,209 valid samples. This dataset allowed them to train neural networks to understand binary code more effectively.
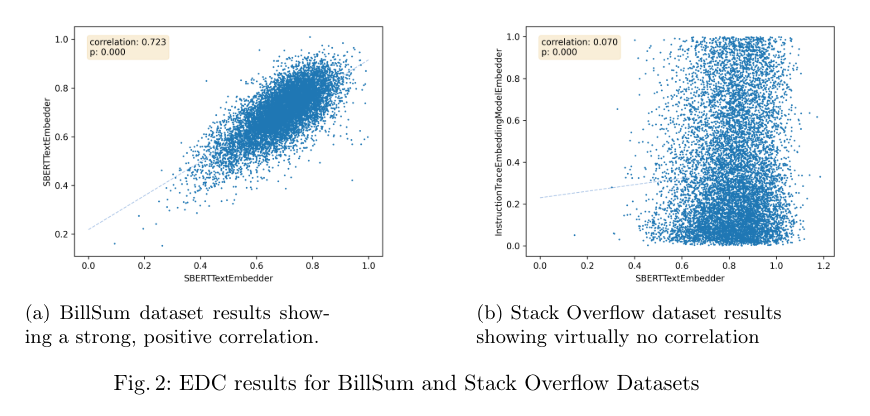
The team developed a new methodology called Embedding Distance Correlation (EDC) to evaluate their dataset. To determine the dataset’s quality, they aimed to measure the correlation between binary samples and their associated English descriptions. Unfortunately, their findings indicated a low correlation between the binary code and the textual descriptions, similar to other datasets. The team’s method highlighted that their dataset was insufficient to train a model effectively because the correlation between the code and the explanations was too weak to provide reliable results.

In conclusion, the study reveals the complexity of developing high-quality datasets that adequately train machine-learning models to summarize code. Despite the significant effort required to build a dataset from over 1.1 million entries, the results suggest that improved techniques for data augmentation and evaluation are still needed. The researchers highlighted the challenges in building datasets that can sufficiently capture the nuances of binary code and translate them into meaningful descriptions, indicating that further research and innovation are required in this field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.