
As digital interactions become increasingly complex, the demand for sophisticated analytical tools to understand and process this diverse data intensifies. The core challenge involves integrating distinct data types, primarily images, and text, to create models that can effectively interpret and respond to multimodal inputs. This challenge is critical for applications ranging from automated content generation to enhanced interactive systems.
Existing research includes models like LLaVa-NeXT and MM1, which are known for their robust multimodal capabilities. The LLaVa-NeXT series, particularly the 34B variant, and MM1-Chat models have set benchmarks in visual question answering and image-text integration. Gemini models like Gemini 1.0 Pro further push performance in complex AI tasks. DeepSeek-VL specializes in visual question answering, while Claude 3 Haiku excels in generating narrative content from visual inputs, showcasing diverse approaches to blending visual and textual data within AI frameworks.
Hugging Face Researchers have introduced Idefics2, a powerful 8B parameter vision-language model designed to enhance the integration of text and image processing within a single framework. This method contrasts with previous models, which often required the resizing of images to fixed dimensions, potentially compromising the detail and quality of visual data. This capability, derived from the NaViT strategy, enables Idefics2 to process visual information more accurately and efficiently. Integrating visual features into the language backbone via learned Perceiver pooling and an MLP modality projection further distinguishes this model, facilitating a deeper and more nuanced understanding of multimodal inputs.
The model was pre-trained on a blend of publicly available resources, including Interleaved web documents, image-caption pairs from the Public Multimodal Dataset and LAION-COCO, and specialized OCR data from PDFA, IDL, and Rendered-text. Moreover, Idefics2 was fine-tuned using “The Cauldron,” a carefully curated compilation of 50 vision-language datasets. This fine-tuning phase employed technologies like Lora for adaptive learning and specific fine-tuning strategies for newly initialized parameters in the modality connector, which underpins the distinct functionalities of its various versions—ranging from the generalist base model to the conversationally adept Idefics2-8B-Chatty, poised for release. Each version is designed to excel in different scenarios, from basic multimodal tasks to complex, long-duration interactions.
Versions of Idefics2:
Idefics2-8B-Base:
This version serves as the foundation of the Idefics2 series. It has 8 billion parameters and is designed to handle general multimodal tasks. The base model is pre-trained on a diverse dataset, including web documents, image-caption pairs, and OCR data, making it robust for many basic vision-language tasks.
Idefics2-8B:
The Idefics2-8B extends the base model by incorporating fine-tuning on ‘The Cauldron,’ a specially prepared dataset consisting of 50 manually curated multimodal datasets and text-only instruction fine-tuning datasets. This version is tailored to perform better on complex instruction-following tasks, enhancing its ability to understand and process multimodal inputs more effectively.
Idefics2-8B-Chatty (Coming Soon):
Anticipated as an advancement over the existing models, the Idefics2-8B-Chatty is designed for long conversations and deeper contextual understanding. It is further fine-tuned for dialogue applications, making it ideal for scenarios that require extended interactions, such as customer service bots or interactive storytelling applications.
Improvements over Idefics1:
- Idefics2 utilizes the NaViT strategy for processing images in native resolutions, enhancing visual data integrity.
- Enhanced OCR capabilities through specialized data integration improve text transcription accuracy.
- Simplified architecture using vision encoder and Perceiver pooling boosts performance significantly over Idefics1.
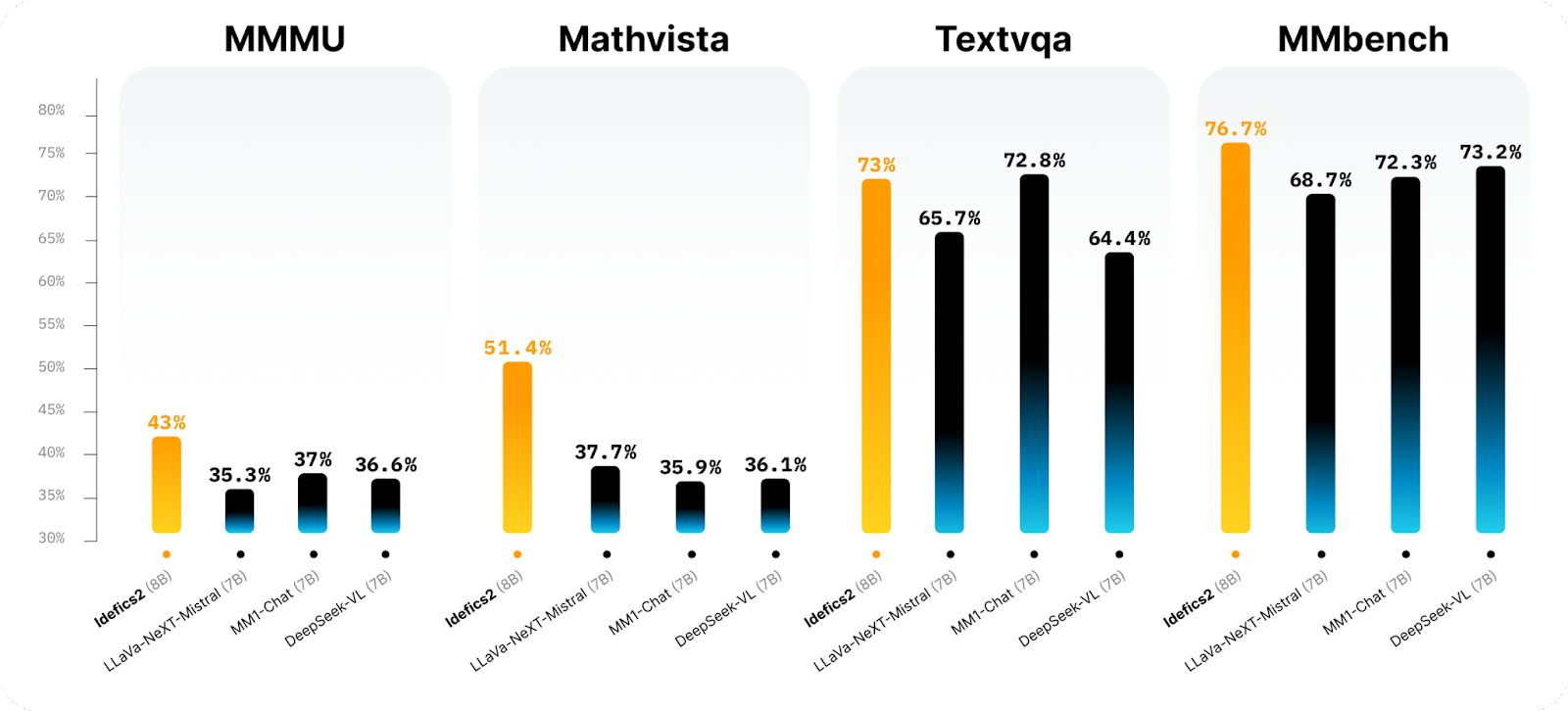
In testing, Idefics2 demonstrated exceptional performance across multiple benchmarks. The model achieved an 81.2% accuracy in Visual Question Answering (VQA) on standard benchmarks, significantly surpassing its predecessor, Idefics1. Furthermore, Idefics2 showed a 20% improvement in character recognition accuracy in document-based OCR tasks compared to earlier models. The enhancements in OCR capabilities specifically reduced the error rate from 5.6% to 3.2%, establishing its efficacy in practical applications requiring high levels of accuracy in text extraction and interpretation.
To conclude, the research introduced Idefics2, a visionary vision-language model that integrates native image resolution processing and advanced OCR capabilities. The model demonstrates significant advancements in multimodal AI, achieving top-tier results in visual question answering and text extraction tasks. By maintaining the integrity of visual data and enhancing text recognition accuracy, Idefics2 represents a substantial leap forward, promising to facilitate more accurate and efficient AI applications in fields requiring sophisticated multimodal analysis.
Check out the HF Project Page and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.