
Language models are pivotal in advancing artificial intelligence (AI), enhancing how machines process and generate human-like text. As these models become increasingly complex, they leverage expansive data volumes and sophisticated architectures to optimize performance and efficiency. One pressing challenge in this domain is the development of models that manage extensive datasets without prohibitive computational costs. Traditional models often require substantial resources, which hinders practical application and scalability.
Existing research in large language models (LLMs) includes foundational frameworks like GPT-3 by OpenAI and BERT by Google, utilizing traditional Transformer architectures. Models such as LLaMA by Meta and T5 by Google have focused on refining training and inference efficiency. Innovations like Sparse and Switch Transformers have explored more efficient attention mechanisms and Mixture-of-Experts (MoE) architectures, respectively. These models aim to balance computational demands with performance, influencing subsequent developments like GShard and Switch Transformer in optimizing routing mechanisms and load balancing among model experts.
Researchers from DeepSeek-AI have introduced DeepSeek-V2, a sophisticated MoE language model, leveraging an innovative Multi-head Latent Attention (MLA) and DeepSeekMoE architecture. This methodology uniquely addresses efficiency by activating only a fraction of its total parameters per task, drastically cutting down computational costs while maintaining high performance. The MLA mechanism significantly reduces the Key-Value cache required during inference, streamlining the processing without compromising the depth of contextual understanding.
DeepSeek-V2’s methodology centers around its advanced training protocols and evaluation of comprehensive datasets. The model was pre-trained using a meticulously constructed corpus containing 8.1 trillion tokens sourced from various high-quality multilingual datasets. This training leveraged Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to refine performance and adaptability across diverse scenarios. Evaluations were conducted using a set of standardized benchmarks to measure the model’s efficacy in real-world applications. The framework utilized, including employing Multi-head Latent Attention and Rotary Position Embedding, was critical in ensuring the model’s efficiency and effectiveness without excessive computational demands.
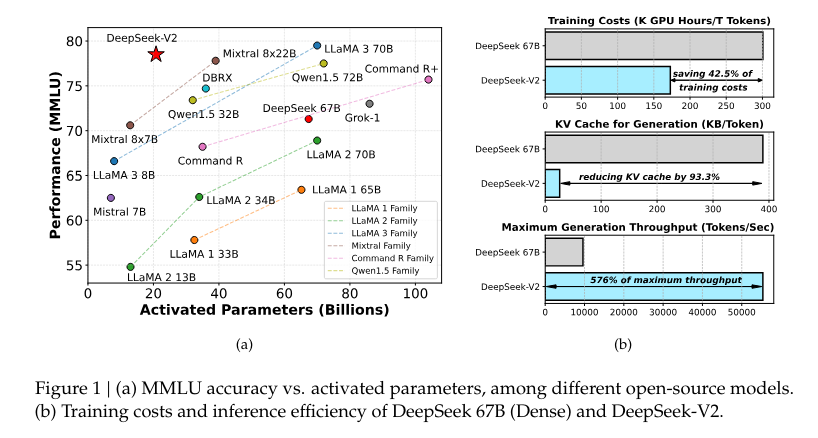
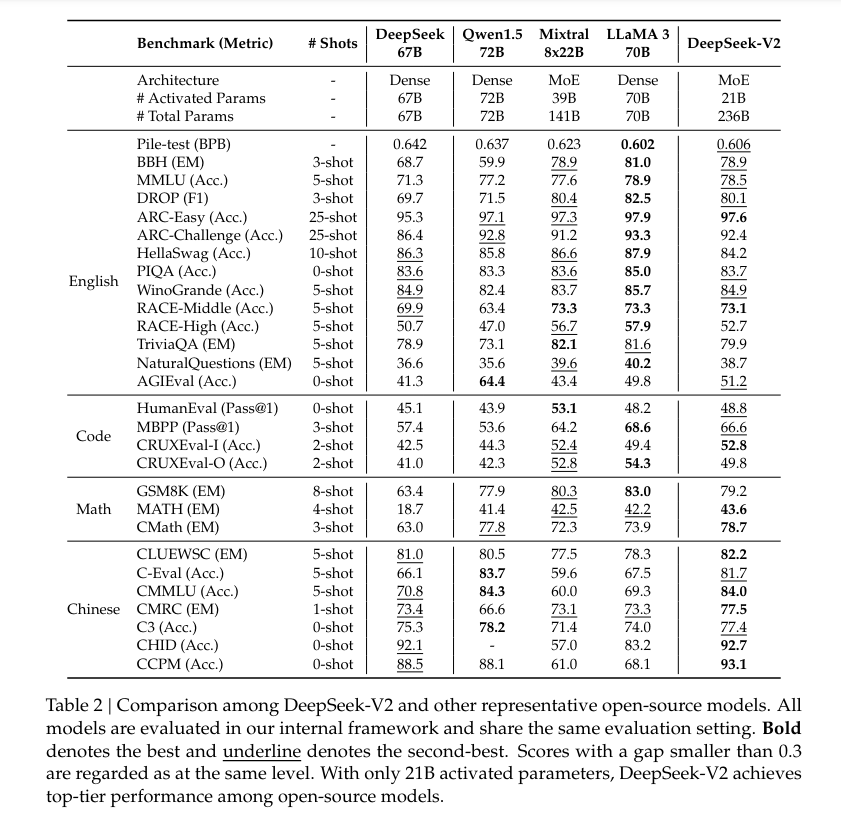
DeepSeek-V2 demonstrated significant improvements in efficiency and performance metrics. Compared to its predecessor, DeepSeek 67 B, the model achieved a 42.5% reduction in training costs and a 93.3% reduction in Key-Value cache size. Moreover, it increased the maximum generation throughput by 5.76 times. In benchmark tests, DeepSeek-V2, with only 21 billion activated parameters, consistently outperformed other open-source models, ranking highly on a variety of performance metrics across different language tasks. This quantifiable success highlights DeepSeek-V2’s practical effectiveness in deploying advanced language model technology.
To conclude, DeepSeek-V2, developed by DeepSeek-AI, introduces significant advancements in language model technology through its Mixture-of-Experts architecture and Multi-head Latent Attention mechanism. This model successfully reduces computational demands while enhancing performance, evidenced by its dramatic cuts in training costs and improved processing speed. By demonstrating robust efficacy across varied benchmarks, DeepSeek-V2 sets a new standard for efficient, scalable AI models, making it a vital development for future applications in natural language processing and beyond.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.